PageRank algorithm
Typing terms in Google and searching them up yields a lot of results. But why are we getting the results in that order? The answer to that question is the PageRank algorithm. The PageRank algorithm is a way to measure the importance of a webpage by analyzing the quantity and quality of the links that point to it.
How does it work?
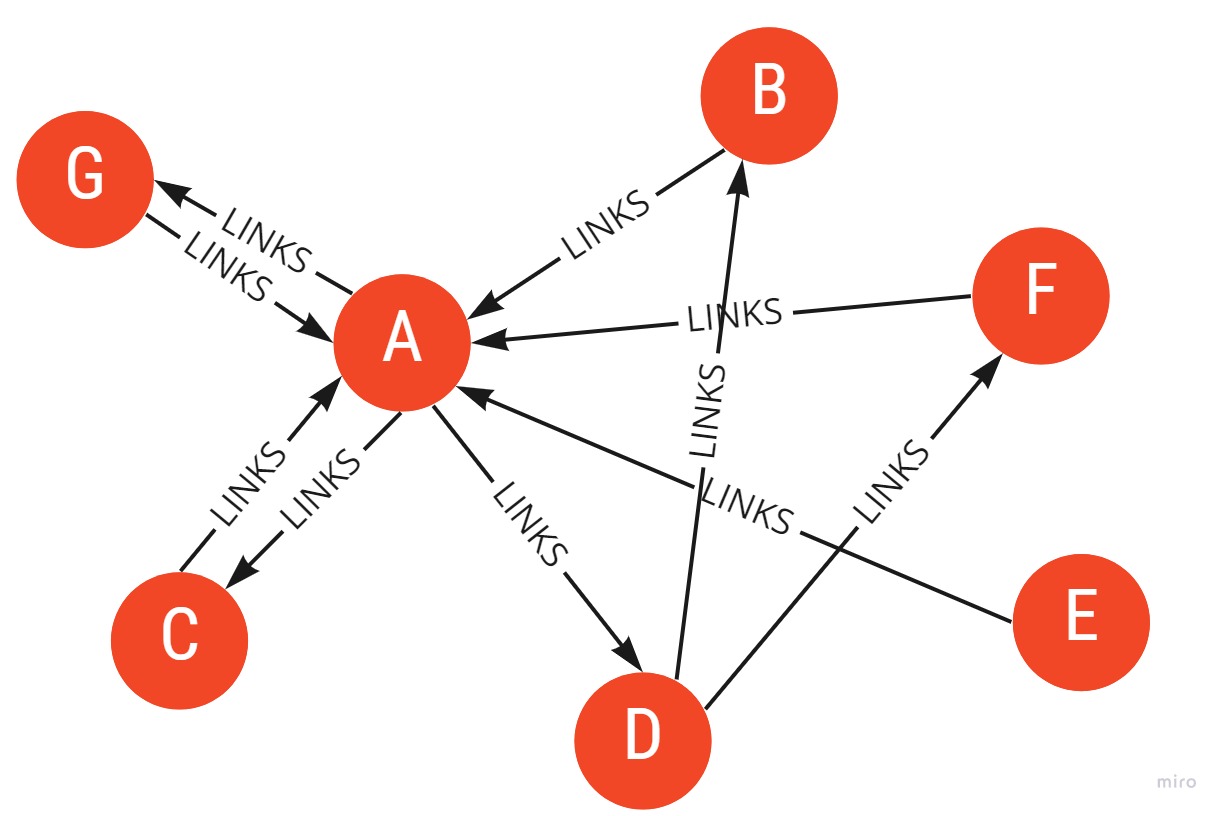
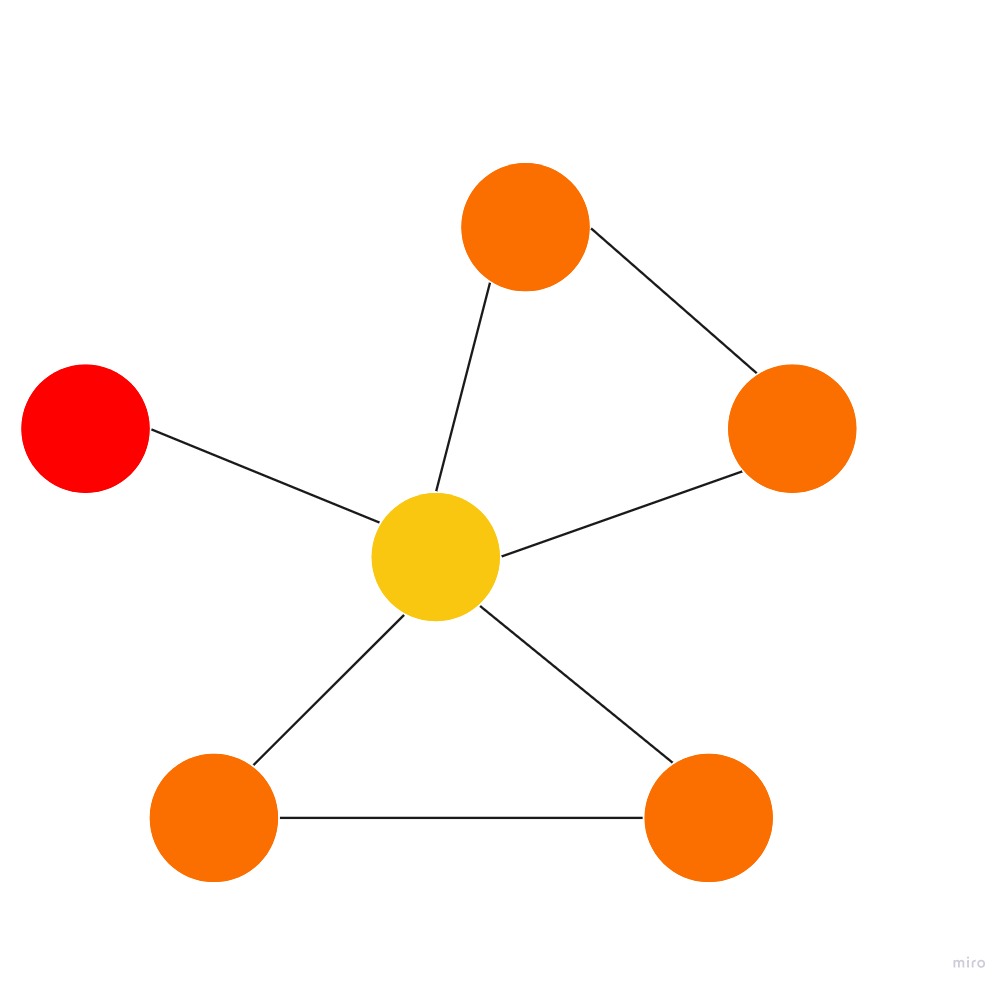
Google interprets a link from page A to page B as a vote from page A to page B. All incoming links can be interpreted as votes. Looking at Figure X, we can say that then, the yellow node is more important than the red node.
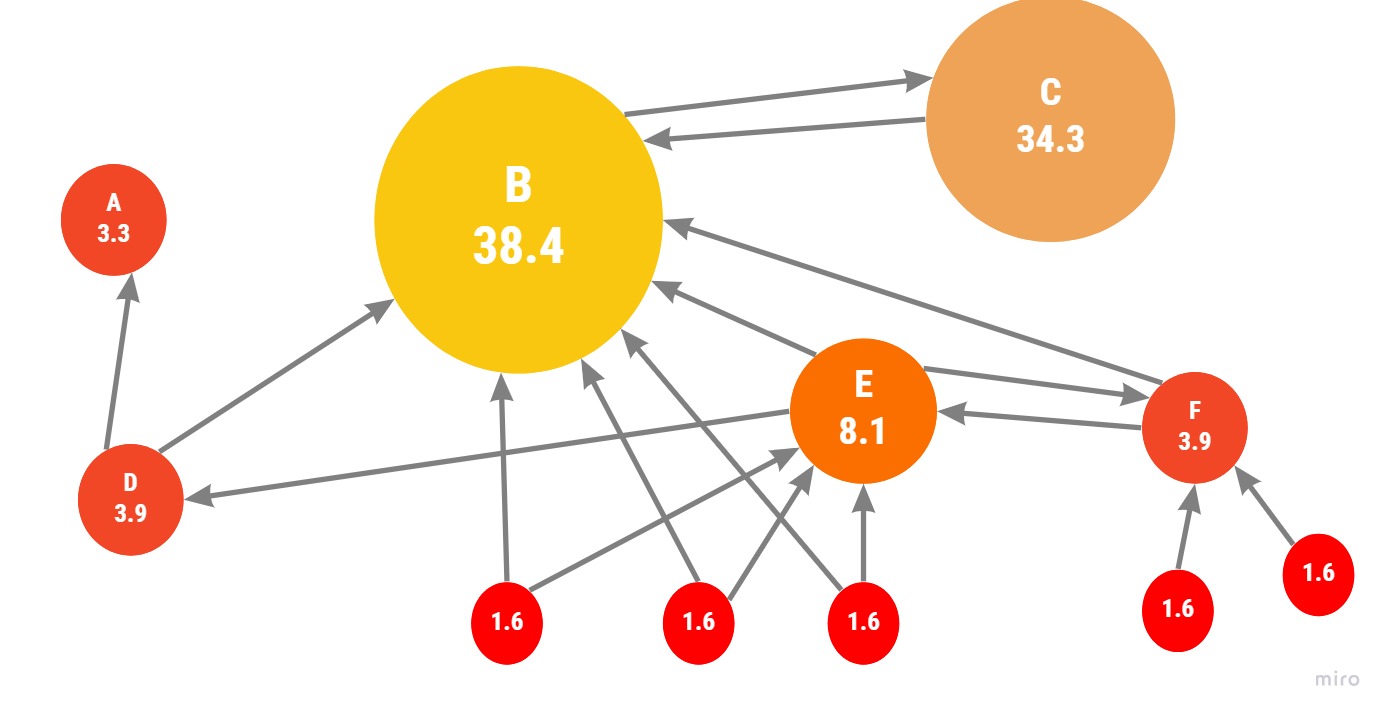
But, it also takes into consideration the “importance” of the page that is “giving” out the vote. If the page that’s casting a vote is more important, the links are worth more and it will help rank up the other pages. Page’s importance is equal to the sum of the votes of its incoming links.
Mathematically, PageRank (PR) is defined as:
PR(A) = (1 - d) + d i=1nPR(Ti)C(Ti)
where Page A has pages T1 to Tn which point to it d is a damping factor set between 0 and 1. It is usually set to 0.85 C(A) is defined as the number of links going out of page A.
The algorithm is robust against spam since it’s not easy for a web page owner to add in links to their page from other important pages. The disadvantage is that it favours the older pages because new pages will not have many links going towards them.
Practical applications
- Determining key species in ecology by mapping the relationship between species in the ecosystem. PageRank allows users to identify the most important species.
- It’s been used to rank public spaces or streets, predicting traffic flow and human movement
- Personalized PageRank is used by Twitter to present users with recommendations of other accounts that they may wish to follow
Pseudocode
n = number of nodes in graph
INIT LIST A
INIT LIST PR
FOR i = 0 to n-1
A[i] = 1/n-1
ENDFOR
d = some value between 0 and 1 (usually 0.85)
FOR i = 0 to n-1
PR[i] = 1-d
FOR EACH page Q that connects to PR[i]
On = number of outgoing edges of Q
PR[i] = PR[i] + d * A[Q]/On
FOR i = 0 to n-1
A[i] = PR[i]
ENDFOR
ENDFOR
ENDFOR
Usage in NetworkX
pagerank(G, alpha=0.85, personalization=None, max_iter=100, tol=1e-06, nstart=None, weight='weight', dangling=None)
Not fast enough? Find 100x faster algorithms here.
Method input
The first input parameter of the method, G, is a NetworkX graph. Undirected graphs will be converted to a directed graph with two directed edges for each undirected edge. The second parameter, alpha, is the damping parameter for PageRank and the default value is 0.85. The fourth parameter, max_iter, is the Maximum number of iterations. The seventh parameter, weight, represents the edge attribute that should be used as the edge weight. If it’s not specified, the weight of all edges will be 1.
For all other parameters, check out the NetworkX Reference Guide.
Method output
The output of the method is a dictionary with nodes as keys and with PageRank as values.
Example
Python’s NetworkX implements the PageRank algorithm as part of its Link Analysis algorithms. In the example below, we will showcase how to use the PageRank algorithm.
- Python code
- Output
- Visualization
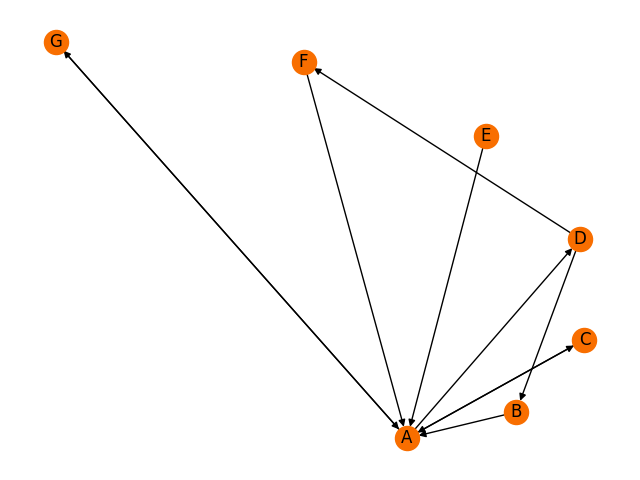
G = nx.DiGraph()
[G.add_node(k) for k in ["A", "B", "C", "D", "E", "F", "G"]]
G.add_edges_from([('G','A'), ('A','G'),('B','A'),
('C','A'),('A','C'),('A','D'),
('E','A'),('F','A'),('D','B'),
('D','F')])
ppr1 = nx.pagerank(G)
print(“Page rank value: ” + ppr1)
pos = nx.spiral_layout(G)
nx.draw(G, pos, with_labels = True, node_color="#f86e00")
plt.show()
Page rank values: {'A': 0.408074514346756, 'B': 0.07967426232810562, 'C': 0.13704946318948708, 'D': 0.13704946318948708, 'E': 0.021428571428571432, 'F': 0.07967426232810562, 'G': 0.13704946318948708}
Where to next?
There are many graph algorithms libraries out there, with their own implementations of PageRank algorithm. NetworkX's algorithms are written in Python, and there are many other libraries that offer faster C++ implementations, such as MAGE, a graph algorithms library developed by Memgraph team.